
※本サイトは一部アフィリエイト広告を利用しています。
目次
クローラーとは?どんな意味があるの?
クローラーとは、簡単にいうと、インターネット上にある情報を集めるためのロボットです。
英語でクロール(crawl)とは「這う」という意味を持ち、インターネット上にあるサイトの情報を這うように取得するイメージから、クローラーと呼ばれています。
また、クローラーは自動で情報を集めるものが多く、よく「スパイダー」や「ロボット」、「ボット(bot)」とも呼ばれます。主にGoogleやBingなどの大型検索エンジンが、情報を集めるために活用しています。
クローラーが集めた情報は、データベースにインデックス(保存)され、検索エンジンが最適な検索結果を表示するために使われます。
したがって、Webページを変更したときは、インデックスをリクエストして(こちらから要求するということですね)クローラーを回し、Webページを変更したことを適切に検索エンジンへと伝えることが大切です。
インデックスについて詳しく知りたい方は以下の記事をご覧ください。
 インデックスとは?わかりやすいIT・SEO用語解説
インデックスとは?わかりやすいIT・SEO用語解説クローラーの種類
クローラーの種類は、主に以下のようなものがあります。
- Googlebot:Google
- Yahoo! Slurp:Yahoo!
- Bingbot:マイクロソフト社の検索エンジンBing
- baiduspider:百度
- Yetibot:Naver
- ManifoldCF:Apache
Googleには、Web検索用のGooglebot以外にも、画像検索用のGooglebot-Image、モバイル検索用のGooglebot-Mobileなど、多数のクローラーが存在します。
また、国内の検索エンジンの使用比率は以下のようになります。
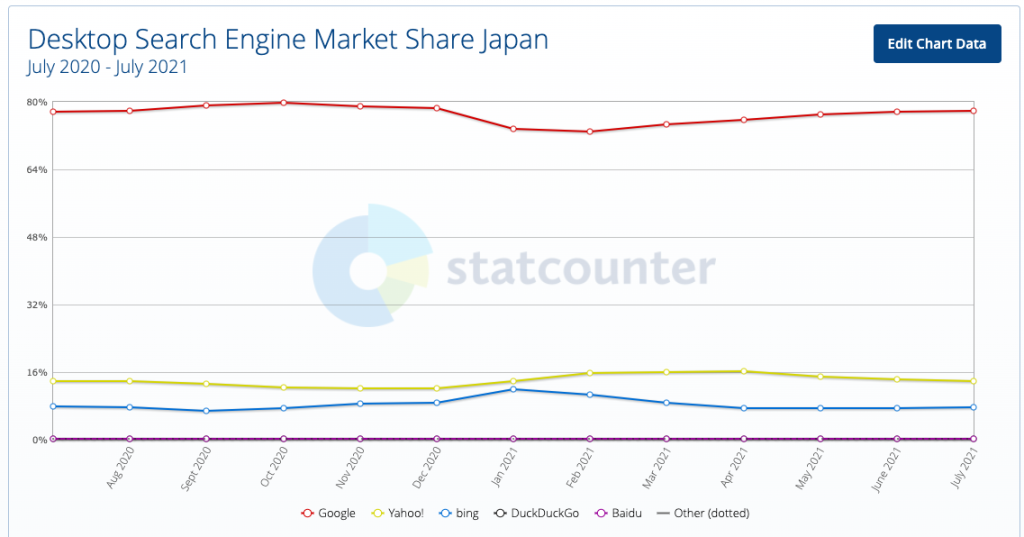
- Google:77.82%
- Yahoo!:13.82%
- bing : 7.77%
- Baidu : 0.18%
出典:https://gs.statcounter.com/search-engine-market-share/desktop/japan/#monthly-202007-202107
Yahoo!の中身はGoogle?
実は、現在のYahoo!の検索エンジンはGoogleの検索エンジンを採用しており、Yahoo! Slurpというクローラーはほとんど使われていません。
したがって、日本のインターネット検索のほとんどは、Googleの検索エンジンによって行われていることになるので、基本的にはGoogleに対してのSEO対策を行うべき、と考えていただいて問題ありません。
クローラーが自分のサイトに来たか確認するには?
本項では、クローラーが自分のサイトを訪れて、きちんと情報収拾をしてくれているかを確認する方法を解説します。
本項は、少し秘術的な内容になりますので、クローラーに関する基本的なSEO対策のみを知りたい方は、本記事内のクローラーのために最適化しようをご覧ください。
さて、クローラーが自分のサイトに訪れたか確認する方法は、以下3つの方法があります。
- site:で確認
- タイトル、メタディスクリプションが変わったかどうかで確認
- クロールの統計情報を確認
詳しく解説していきます。
1. site:で確認
新しい記事を公開した後にクローラーがきちんと訪れたか確認するときに使える方法です。
以下のようなキーワードでGoogle検索すると、クローラーが新しい記事を訪れ、検索エンジンに認識されたか確認することができます。
site:(新しく公開した記事のURL)例えば当サイトであれば下記のようなキーワードで検索します。
site:https://val-works.com/bowned/しっかりクローラーが回り、検索エンジンに認識されている場合、以下のように表示されます。
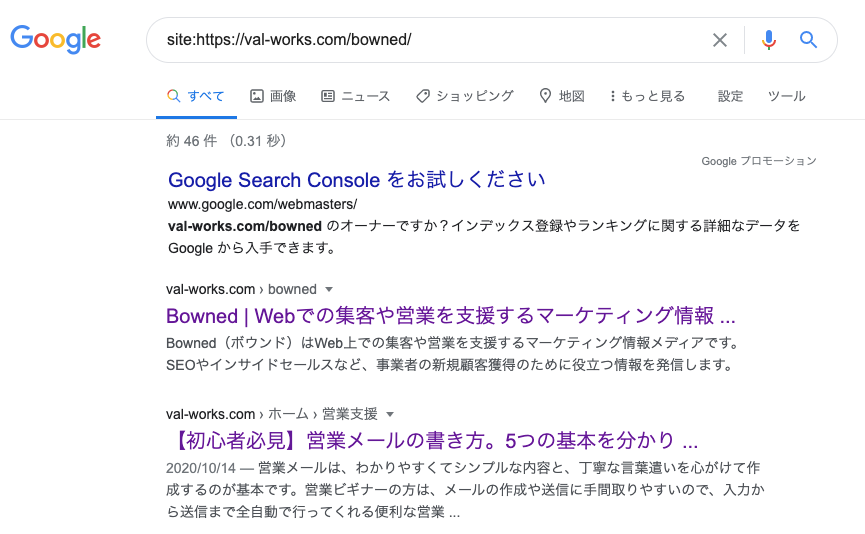
このように表示されれば、一安心です。新規記事に順位が付くことを気長に待ちましょう。
もし認識されていない場合は、以下のように表示されます。
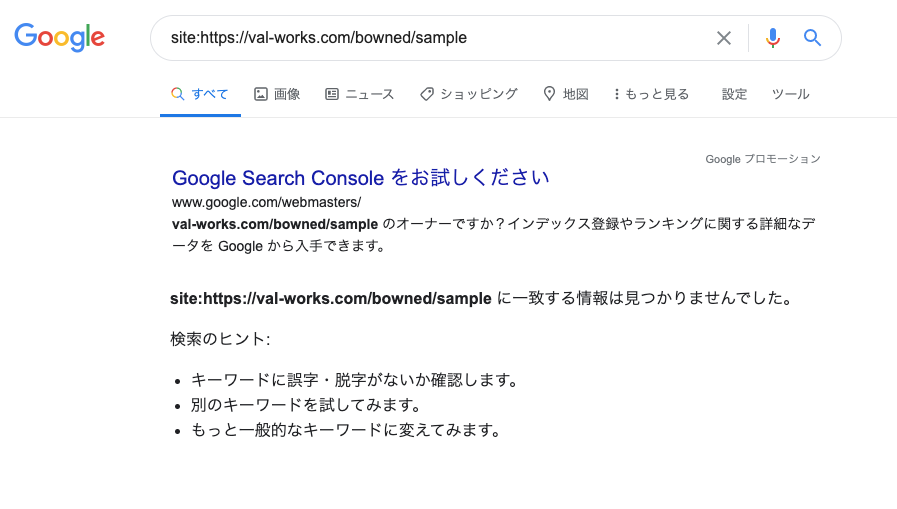
もちろん公開したばかりの記事はインデックスされるまでに多少の時間が必要ですが、何ヶ月経っても上記のような画面が表示される場合は検索エンジンに認識されていない可能性があります。
このままクローラーが訪れず、検索エンジンに認識されないと、いつまでたっても順位が付かないので、何らかの対策を講じる必要があります。
新しい記事が認識されていない場合は、クローラーに新しい記事を見に来てもらえるようGoogleコンソールでリクエストすることができます。
弊社では、新規記事を出したらすぐにインデックスをリクエストし、クローラーに来てもらうことをルール化しています。
2. タイトル、メタディスクリプションが変わったかどうかで確認
新しく公開した記事にクローラーが回ったかは、site:で確認できます。
しかし、既に出した記事を変更したときに確認するにはどうしたら良いのでしょうか。
既にある記事の変更を検索エンジンに認識してもらったかどうかは、検索結果のタイトル、メタディスクリプションの変化で確認できます。
検索結果の上部分がタイトル、下の四角部分がメタディスクリプションです。
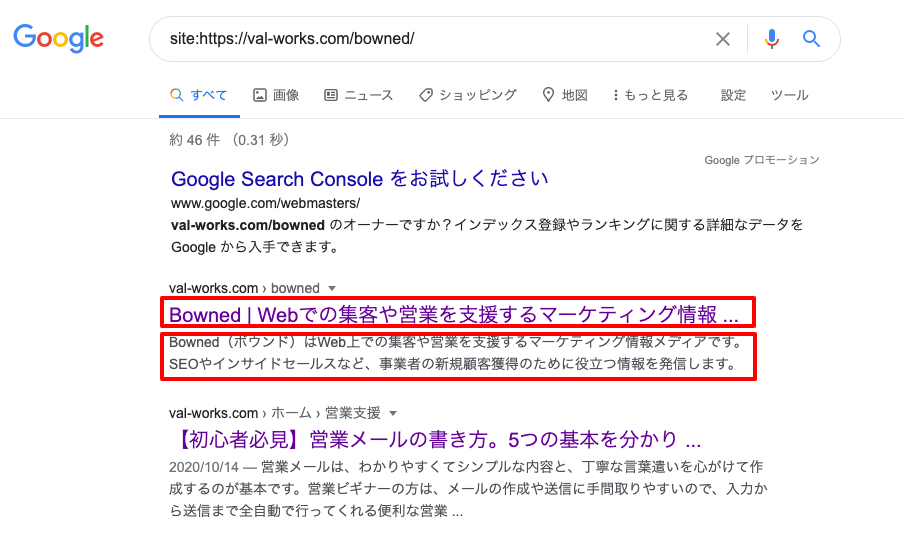
メタディスクリプションを検索結果に表示させるため、検索結果で確認するときも、site:URLで確認しましょう。
しかし、この方法には弱点があり、タイトルまたは、メタディスクリプションを変更していないと、クローラーが回ってきたか確認できないのです。
そのため、検索結果に出てこない本文を変更しても、この方法では、変更が検索エンジンに認識されたかわからないので注意しましょう。
実を言うと、インデックスをリクエストすれば、多くの場合1時間以内にクローラーは回ってくるので問題ありません(もちろん例外はあります)。
したがって、検索エンジンに認識されたか過度に心配する必要は少ないのですが、どうしても確認したいと言う方は、メタディスクリプションの語尾を変更しましょう。
メタディスクリプションなら、SEO的にもあまり影響がなく、語尾を変える程度ならば全く問題ないでしょう。
3. クロールの統計情報を確認
Googleサーチコンソールにある、クロールの統計情報でも、クローラーが来たかどうかを確認できます。
まず、サーチコンソールの設定から「クロールの統計情報」にアクセスし、確認したいサイトのプロパティを選択します。すると、クロールの統計情報が表示されます。クロールの統計情報では、クローラーが訪れたページの数を日付別でみることが可能です。
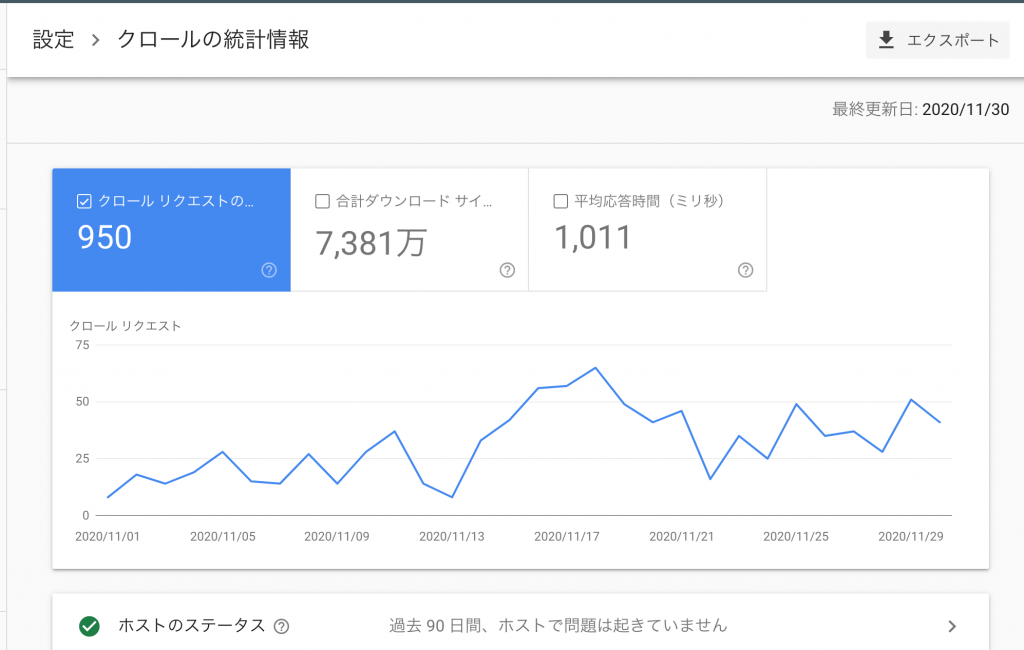
しかし、この方法では、どのページにクローラーが回ったのか詳細にわからないため、個別のページごとに確認したい場合はあまり役に立ちません。
あくまで、全体としてクローラーがどのくらいきているか把握する手段であることを覚えておきましょう。
余談ですが、クロールの統計情報では1日にダウンロードされるキロバイト数とページのダウンロード時間 (ミリ秒)も確認することができます。
特に、ページのダウンロード時間は検索順位に影響するとも言われるので、遅過ぎないか一度確認してみることをおすすめします。
クロールバジェットとは?
クロールバジェットとは、Googleが設けているクロール数の上限です。イメージとしては、クローラーの体力のようなものになります。もし、クロールバジェットに達してしまった場合、それ以上のページはクロールされません。
これに関して、何か対策はあるのでしょうか。
結論から言うと、1,000記事以下のサイトでは、Googleバジェットの上限に達することはまずありません。したがって、ほとんどの人は気にする必要はありません。
Googleのジョン・ミューラー氏は、Googleバジェットを気にする必要があるのは、クローラーが無限にクロールを繰り返す必要がある、URLが非常に複雑かつ無尽蔵にあるサイトだと言っています。
クローラーの巡回頻度を制限できる
Googleのクローラーの巡回頻度はサーチコンソールで制限することができます。とはいっても、ほとんどの人はクローラーの巡回頻度を制限する必要はありません。
必要なのは、サービスの形態上クローラーが回りすぎると、サーバーに負荷がかかる、というケースです。

そういった場合は、上記の「Google の最大クロール頻度を制限する」にチェックすることで、サーバの負担を軽くすることができます。
クローラーと検索エンジン・SEOの関係
もし、サイト表示のテストをしたい場合や、Googleの検索エンジンに認識されたくないページがある場合は、クローラーをブロックしましょう。直接ユーザーの役に立たないページがGoogleに認識されると、サイト自体の評価が下がってしまう可能性があります。
※筆者はインデックスされなければ、問題ないと思っていますが、可能性は0ではありません。
クローラーによって認識されないようにするためには、robots.txtファイルを作成し、その中に以下のコードを記述しましょう。
例:https://val-works.com/bowned/sample-test/ でクローラーをブロックしたい場合
User-agent: Googlebot
Disallow: /bowned/sample-test/※上記の例はrobots.txtをルートディレクトリに配置した際の例です。パスは対象によって適宣変更してください
SEOでは、このようにリスクを1つずつ排除していくことが大切です。
クローラーのために最適化しよう
ご自身のWebサイトを、検索エンジンに適切に評価してもらうには、クローラーへの最適化が必須です。
クローラーの最適化に必須知識!クローラビリティとは?
クローラーのための最適化を理解するには、クローラビリティという概念を理解する必要があります。前提知識として、まずしっかりと理解しておきましょう。
クローラビリティとは、どのくらいクローラーがサイト内を回りやすいかを表しています。クローラーにサイトの隅々までクロールしてもらい、サイトを適切に評価してもらうことは、SEO的に非常に大切です。
そのため、検索順位を上げてサイトに訪れるユーザーを増やしたいという場合は、クローラビリティを向上させるべきです。
クローラビリティを向上させるための具体的な施策について解説していきます。クローラー最適化のための施策は、主に以下の7つです。
- 内部リンクの最適化をする
- 被リンクを増やす
- サイトマップの送信
- インデックスのリクエストは忘れずにする
- 内部リンクのない記事をなくす
- パンくずリストを設定する
- URLの正規化
1. 内部リンクの最適化をする
サイト内の内部リンクを適切に張り巡らせることは、SEO的に非常に重要です。その理由は、内部リンクの最適化はクローラビリティを向上させるだけでなく、ページの評価を上げるためにも活用できるからです。
内部リンクの貼り方のポイントは以下の2つです。
- 適切な文脈で貼る
- ユーザーがクリックするところに内部リンクを貼る
適切な文脈で貼る
適切な文脈で内部リンクを貼る理由は、ユーザーから見てもGoogleから見ても、関連性のないリンクは不自然に感じるからです。逆に、記事のテーマと関連性の深い見出しの下などに内部リンクを貼れば、Googleから良いリンクだと見なされ、ページ自体の評価が向上します。
ユーザーがクリックするところに内部リンクを貼る
この理由として、クローラーは、ユーザーが頻繁にクリックする場所をクロールすることが挙げられます。そのため、ユーザーがクリックしないような内部リンクを貼ったとしても、クローラーはあまり回らず、クローラビリティの向上への効果は期待できません。つまり、むやみに内部リンクを増やすのは得策ではないでしょう。
2. 被リンクを増やす
被リンクを増やせば、外部からクローラーを呼び込めるため、クローラビリティの向上に効果的です。
また、被リンクを受けるということは、他のサイトから参考にされていたり、引用をされている可能性が高いので、Googleの評価も上がります。
したがって、被リンクを増やすことは、クローラビリティ向上とGoogleの評価向上という2重のSEO効果があるのです。
ただし、低品質なサイトからの被リンクは逆効果となるので注意が必要です。例えば大量に自動生成されたコンテンツや、重複コンテンツのページからの被リンクはペナルティを受けるリスクもあるため絶対に避けるようにしましょう。
3. サイトマップの送信
サイトマップとは、サイト全体の構成をわかりやすくする地図、のようなものです。Googleサーチコンソールでサイトマップは送信することができ、それによって、Googleがサイト構造を把握しやすくなります。
サイトマップを送信するには、サーチコンソールの左側にあるサイトマップをクリックし、サイトマップのURLを入力すれば送信できます。
サイトマップを送信しておけば、全く内部リンクをされていないページもクローラーに見つけてもらいやすくなります。
4. インデックスのリクエストは忘れずにする
サーチコンソールを使いインデックスをリクエストすることで、クローラーをページに回すことができます。
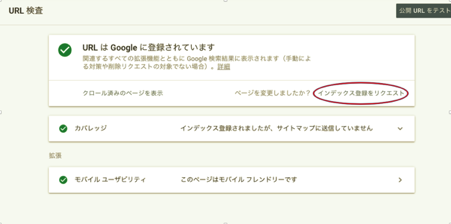
Googleコンソールの一番上の部分にURLを入れ、「インデックスをリクエスト」を押せば完了です。新規記事を公開するたびに、必ずインデックスのリクエストをするようにしましょう。
5. 内部リンクのない記事をなくす
内部リンクのない記事は、他の記事からクローラーが辿り着けないため、クロールされる頻度が極端に少なくなってしまいます。
サイト内に関連する見出しや本文などが全くないのであれば仕方ありませんが、関連する記事がある場合は内部リンクを貼り、クローラーが巡回しやすい構造にしましょう。
関連する見出しや本文がないけど、内部リンクを貼りたいという場合は、内部リンクを貼るための記事の作成がおすすめです。その時は、関連性のある記事を書くことがポイントになります。
前述しましたが、Googleは関連性のある内部リンクを評価します。
6. パンくずリストを設定する
パンくずリストは、ページ上部に表示される以下のような部分のことです。

パンくずリストを設置することで、クローラーがサイト内を巡回しやすくなり、まだ回っていなかったページにも回りやすくなります。
パンくずリストについて詳しく知りたい方は以下の記事をご覧ください。
 パンくずリストとは?メリットと種類を解説
パンくずリストとは?メリットと種類を解説7. URLの正規化
内容が全く同じページでも、wwwがあるURL、ないURLが存在していたり、URL末尾に /index.html があるものとないものが存在しているサイトを、たまに見かけます。
これらは、GoogleからするとURLが違うため、内容が全く同じページがサイト内に存在する、つまり、重複コンテンツだと判断されてしまう可能性があります。重複コンテンツと見なされた場合、サイト自体の評価が下がり、SEO的に問題があります。
また、重複コンテンツだとみなされなかったとしても、ページに回るクローラーの数が分散してしまうため、クローラビリティの観点からも問題があります。
そのため、全く同じ内容なのにURLが違うというページがあれば、301リダイレクトをかけて対処しましょう。
ちなみに、このような方法を「URLの正規化」といいます。
まとめ:クローラーとは何か、意味と検索エンジンとの関係を理解しよう
クローラーとは何か、その意味や検索エンジンやSEOとの関係を解説しましたが、いかがだったでしょうか。
このページのポイントは、以下になります。
- クローラーとは、インターネット上の情報を集めるためのロボット
- クローラーには様々な種類がある
- クローラーのためにサイト内を最適化するのはSEO上、非常に大切
クローラーの性質を把握することで、内部リンクの最適化や、被リンクなどについての理解も深めることができます。クローラビリティを意識したサイト運営は、Googleからの評価を上げるために必要な要素ですのでぜひ参考になさってください。



